MQ比较
一、引言
前面已经分析过不同MQ的实现原理,本文则对他们进行一个横向的对比,以便加深记忆,更加深刻的掌握不同消息队列的特性
1.起源
RabbitMQ
RabbitMQ起源于AMQP(Advanced Message Queuing Protocol,高级消息队列协议)标准
AMQP最初是由金融行业的一些公司共同制定的,旨在解决在金融系统中异步通信的需求
RabbitMQ是基于AMQP标准实现的消息队列中间件,最初由LShift开发,并在2007年成为开源项目
RabbitMQ使用Erlang语言开发,其设计目标是实现高可用、高可靠、高性能的分布式消息队列系统
RocketMQ
淘宝原来有一 个自研的 MQ 叫 Notify,Kafka 开源以后,就参考 Kafka 用 Java 语言写了 MetaQ, 所以在涉及思想上有很多跟 Kafka 相似的地方。后来改名字叫 RocketMQ,2012 年开源
Kafka
Kafka 是由 LinkedIn 公司开发的一种分布式、可扩展、高吞吐量的消息系统
它的设计灵感来自于 LinkedIn 在处理大规模实时数据处理和数据流的挑战中的经验和教训
Kafka 借鉴了消息队列的概念,但与传统的消息系统不同的是,Kafka 的设计重点放在了可扩展性和高吞吐量上
2.整体对比
| RabbitMQ | Rocket | Kafka | |
|---|---|---|---|
| 单机吞吐量 | 2.6w/s(消息做持久化) | 11.6w/s | 17.3w/s |
| 开发语言 | Erlang | Java | Scala/Java |
| 主要维护者 | Mozilla/Spring | Alibaba | Apache |
| 订阅形式 | 提供了4种,direct,Topic,Headers和fanout(广播模式) | 基于Topic/MessageTag,按照消息类型、属性进行正则匹配发布-订阅模式 | 基于Topic,按照topic进行正则匹配发布-订阅模式 |
| 持久化 | 支持少量堆积 | 支持大量堆积 | 支持大量堆积 |
| 顺序消息 | 不支持 | 支持 | 支持 |
| 集群方式 | 支持简单集群,镜像集群,对高级集群模式支持不好 | 常用多对Master-Slave模式,开源版本需要手动切换Slave变成Master | 天然划分Leader-Slave,无状态集群,每台服务器既能是Master也能是Slave |
| 性能稳定性 | 好 | 一般 | 较差 |
二、结构对比
1.整体对比
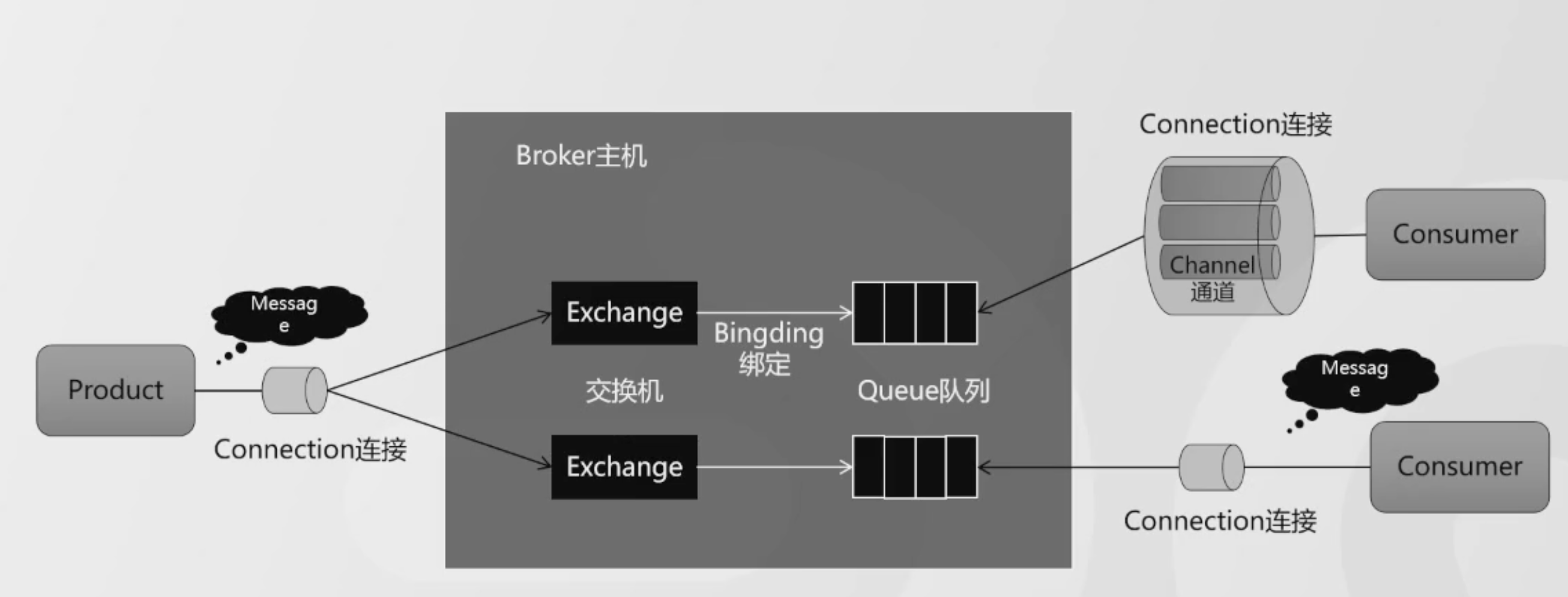
首先是RabbitMQ,它的Broker是由Exchange和Queue来组成的
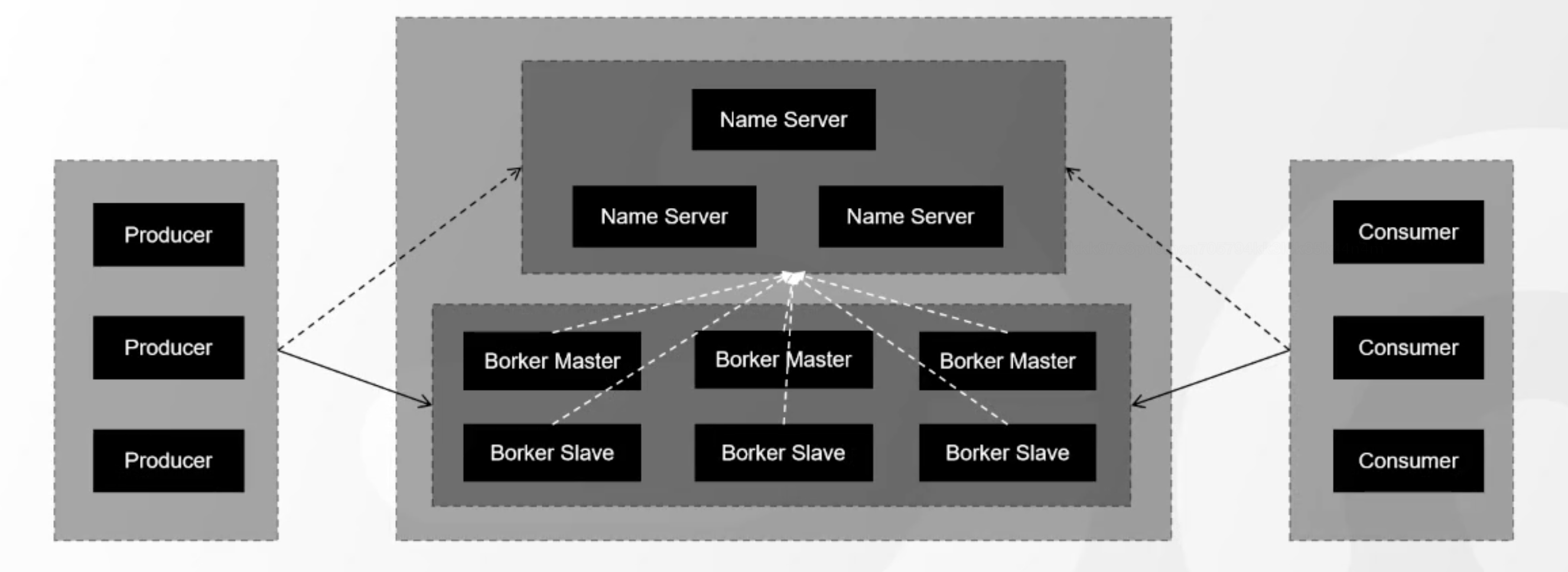
其次是RocketMQ,它并没有使用Zookeeper作为注册中心,而是自定义了NameServer这么个结构,可以认为Broker主机由NameServer与Broker Master+Broker Slave组成的,这里所谓的Master和Slave是指Broker的主副本Master和其他副本Slave,它可以有多个Broker结构
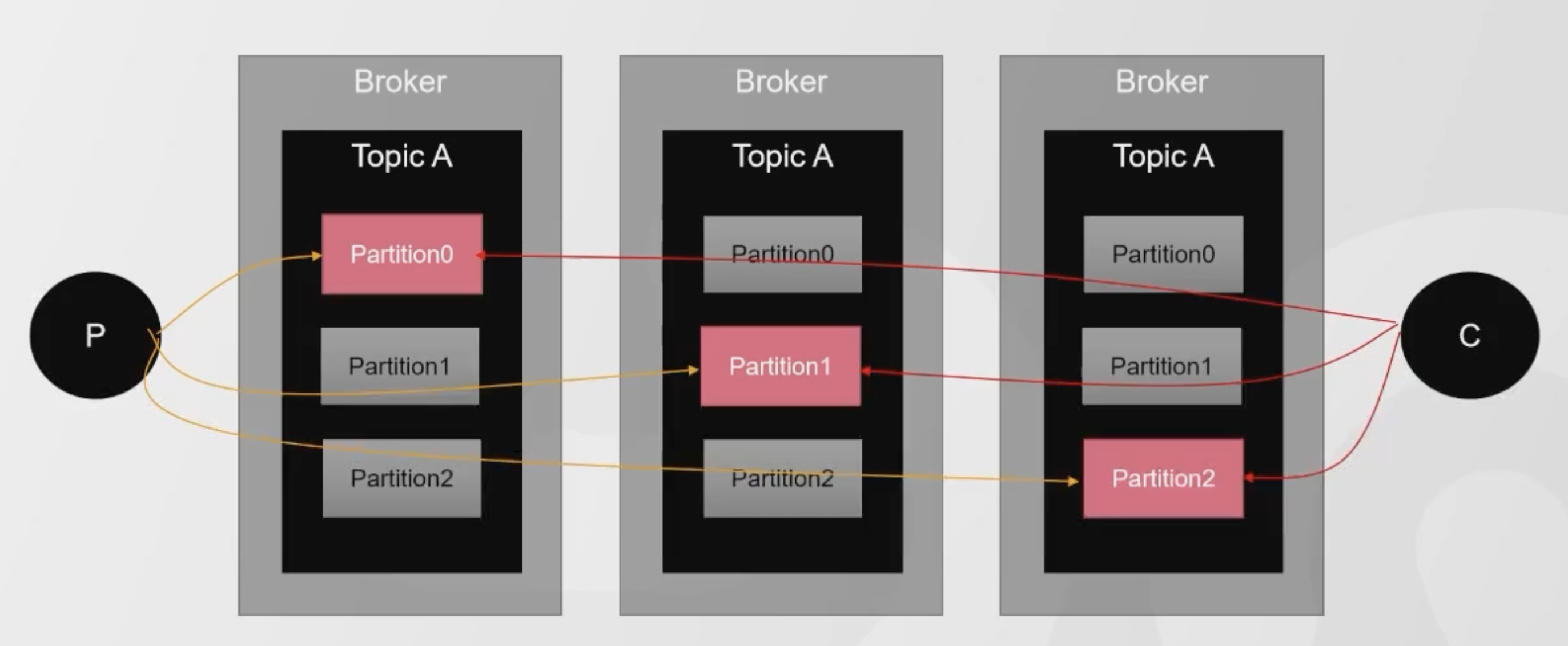
最后是Kafka,它采用Zookeeper作为注册中心,负责维护Kafka机器的存活,状态等信息
在Kafka中,每个Topic划分出来了不同的Partition,它的Partition也是分Leader和Follewer的。其中Follower就是它的Leader的备份
2.生产者
2.1 RabbitMQ
RabbitMQ基于AMQP协议,所以RabbitMQ里面也引入了 Channel 的概念,它是一个虚拟的连接,把它翻译成通道,或者消息信道。这样我们就可以在保持的 TCP 长连接里面去创建和释放 Channel,大大了减少了资源消耗
即交换机Exchange和生产者建立长链接,使用Channel发送消息
rabbitMQ也支持事务,就是发送成功返回一个ack,表示发送成功了
2.2 RocketMQ
RocketMQ的生产者会定时从NameServer拉取路由信息(不用配置 RocketMQ 的服务地址),然后根据路由信息与指定的 Broker 建立 TCP 长连接,从而将消息发送到 Broker 中
发送逻辑一致的 Producer 可以组成一个 Group,这个Group里的Pro
RocketMQ 的生产者同样支持批量发送,不过 List 要自己传进去
即通过NameServer定时拉取路由信息,与Broker下的Master建立长链接,支持Group发送
此外,观察下RocketMQ的结构
在RocketMQ中,生产者根据Topic建立连接,但是这里的Topic是一个逻辑概念,可能是由多个Broker(Master-Slave)组成的,所以就产生了一个问题,那就是生产者要和谁建立联系,发给谁呢?
三种策略,轮询,随机或者未实现
此外,RocketMQ还支持事务消息,具体参考RocketMQ事务消息
2.3 Kafka
Kafka为了减少io次数,开辟了一个发送缓冲区,当缓冲区中发送的消息达到一个阈值之后,会将所有缓冲区中的消息一次发送给Broker
Kafka的事务是使用2PC思想来实现的,引入了有事务协调者TC,事务日志
2.4 小结
生产者,三者和Broker建立连接的过程就都不相同
RabbitMQ是和Exchange之间建立连接,Rocket需要用NameServer上同步过来的路由信息和Topic建立长链接,而Kafka则借助Zookeeper获取路由信息,再与Topic建立连接
RabbitMQ借助Channel发送消息,RocketMQ可以分Group发送,Kafka则先缓存再批量发送
此外,他们都支持事务机制,但是实现方式逐渐复杂
最后,rabbitMQ不支持顺序性
3.消费者
3.1 RabbitMQ
支持Push和Pull模式
- Pull模式:对应的方法是 basicGet,消费者自己获取,实时性低一点,但是能根据自己消费能力获取
- Push模式:对应的方法是 basicConsume,消息队列主动推送给消费者,实时性高,但是消费不过来可能造成消息积压
3.2 RocketMQ
在RocketMQ中,消费者有两种消费方式,分别是集群消费和广播消费
- 集群消费:多个消费者消费同一个Topic的消息,每个消费一部分
- 广播消费:每个消费者都会消费同一个Topic下的所有消息,每个都消费全部消息
按照消费模型来说,RocketMQ也有两种模式,分别是Pull和Push
- Pull:轮询从Broker拉取消息,使用长轮询实现,所谓长轮询就是如果轮询不到相关数据,就会hold住请求,等到有数据或者等一定时间后再返回,返回后客户端立即发起下一次长轮询
- push:Broker推送给Consumer,但是在RocketMQ里面,这个模式实际上是依赖Pull实现的,在Pull模式基础上封装了一层,所以它不是真正的“推模式”
消费逻辑一致的 Consumer 可以组成一个 Group,这时候消息会在 Consumer 之间负载
3.3 Kafka
相比上面的Rocket和RabbitMQ都支持push和pull模式,Kafka的实现只有Pull模式
3.4 小结
只有Kafka只支持Pull模式消费,即消费者自己去拉取消费
三者都支持集群和广播消费,但是实现方式各有不同
RocketMQ和Kafka都有消费者组这个概念,即分组消费
4.消息分发
4.1 RabbitMQ
事实上,消息分发主要是RabbitMQ上的,它指定了不同的方式将消息从交换机分发到Queue上
生产者与交换机之间,有一个routing Key,交换机与Queue之间有一个binding key
主要就是依据这两个key之间的关系进行分发
- direct:直连,两个key完全匹配时才能分发
- topic:使用正则符号#和*匹配
- fanout:广播,全都发,Queue都能收到
每个消费者可以订阅多个queue,但是每个queue只能被一个消费者消费
4.2 RocketMQ
在RocketMQ中,生产者与消费者都是依靠Topic进行联系的,但是需要注意,在RocketMQ中,Topic是一个逻辑概念,实际上是与Broker建立的联系,默认只有Master参与读写
Topic 跟生产者和消费者都是多对多的关系,一个生产者可以发送消息到多个Topic,一个消费者也可以订阅多个Topic
4.3 Kafka
首先,在Kafka中,生产和消费也都是与Topic来建立的连接
Kafka采用了分区的思想,一个Topic划分成了不同的Partition,而且每个Partition还采用了分Replica备份的思路,只有作为Leader的Partition具有读写能力,Follower只做灾备
所以很明显,无论生产者,还是消费者,都是和Partition建立的联系
在Kafka中,引入了消费者组的概念,用group id来配置,消费同一个 Topic 的消费者不一定是同一个组,只有 group id 相同的消费者才是同一个消费者组
此外注意:同一个 Group 中的消费者,不能消费相同的Partition——Partition 要在消费者之间分配
4.3 小结
RocketMQ和Kafka都是和Topic建立连接,但是区别是,在RocketMQ中,Topic是一个抽象逻辑概念,在Kafka当中则是真的存在这么一个结构
RocketMQ可以无所顾忌,多对多随便连接,而Kafka要考虑消费者组,同一个组内的消费者不能消费同一个partition两次
5.持久化
5.1 RabbitMQ
内存与磁盘都存储数据,内存到阈值了就换页到磁盘,磁盘到阈值就卡住,不让生产了
5.2 RocketMQ
同一个Topic内的消息都写入到一个文件中
这样缺点是每个消费者都要维护已经消费到的位置
数据存在磁盘上还那么快是因为采用了Page Cache和零拷贝技术
Page Cache就是预读缓冲区
零拷贝就是直接把Page Cache的数据在用户空间中做一个地址映射,就可以直接读取内存了
这里的零拷贝采用的是MMAP
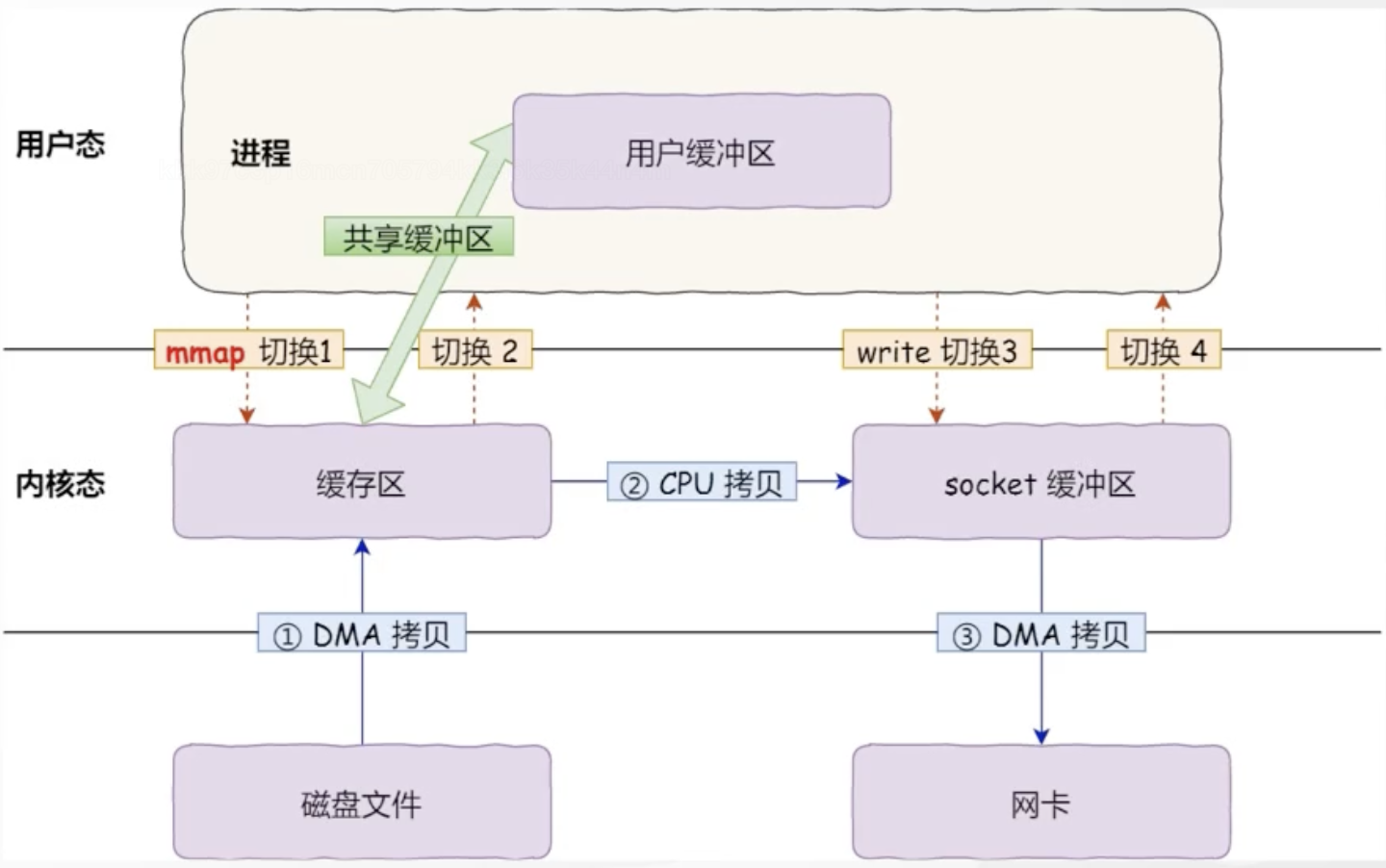
5.3 Kafka
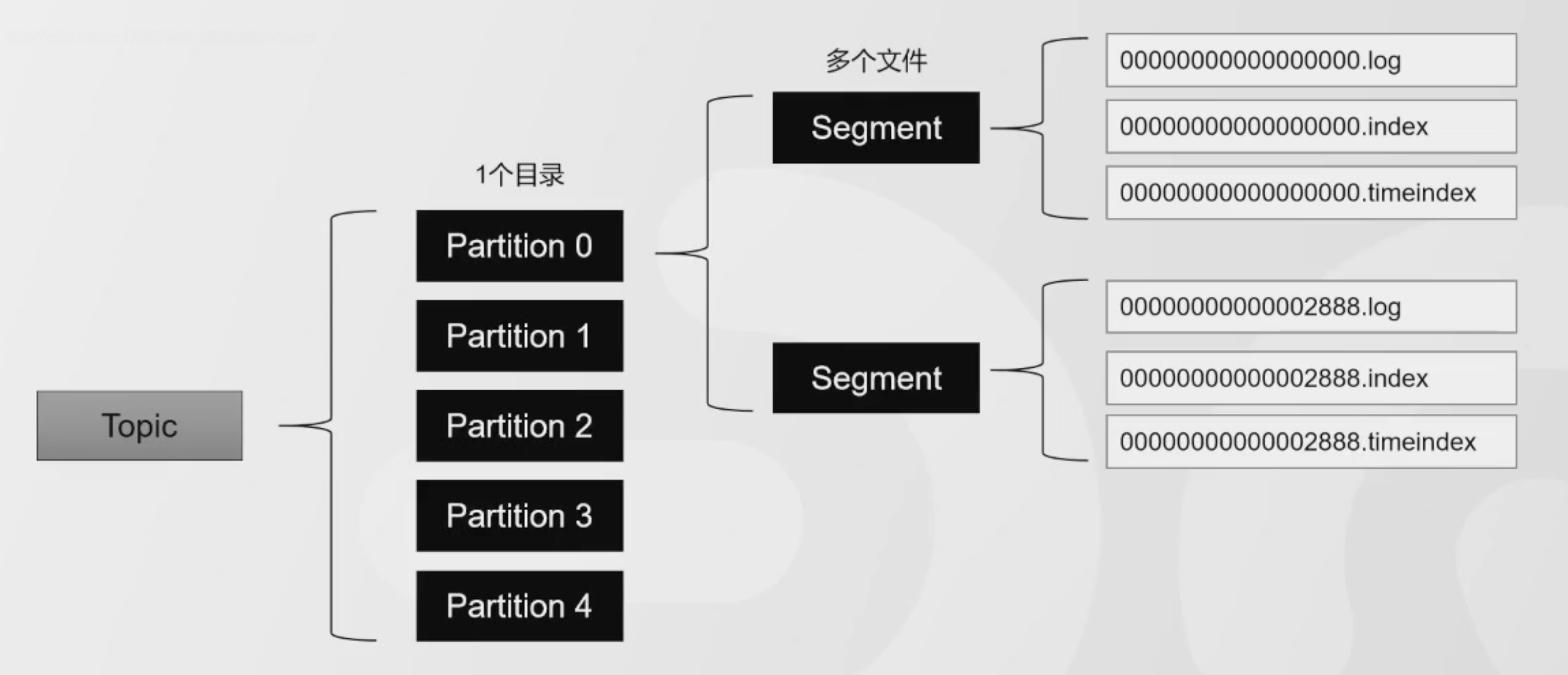
存储了很多不同格式的文件,比如日志文件,索引文件等,整体结构如下
消息慢了要么删(老数据),要么压缩(只留最新key)
那为什么Kafka数据存储在磁盘还那么快呢?
顺序io:追加到文件末尾
索引
批量读写和压缩
零拷贝:直接从DMA到网卡,是sendfile形式零拷贝
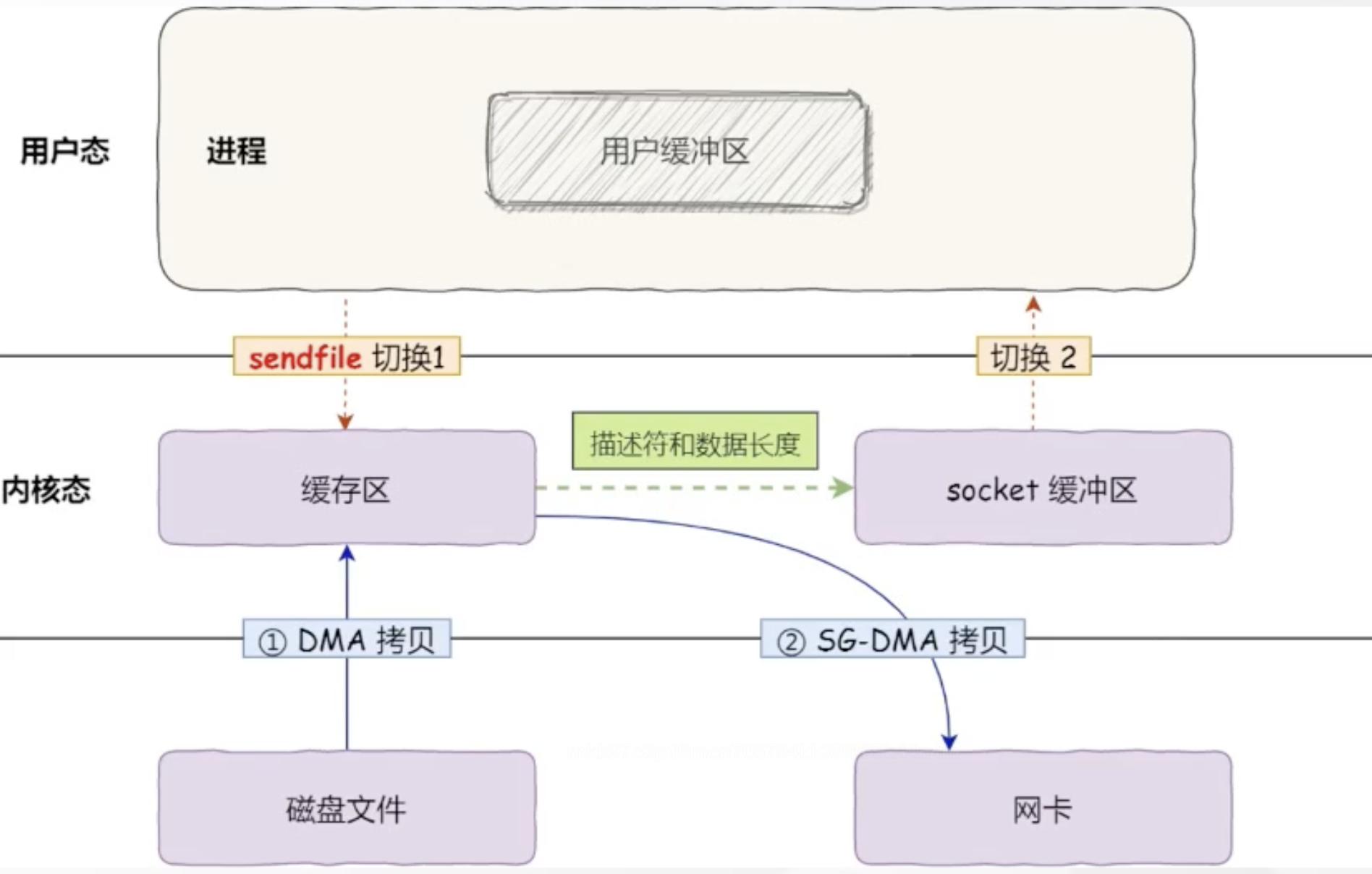
三、总结
从上面的对比可以看出,三种消息队列虽然实现功能类似,但是实现方式有很大不同
算是相同功能每个都有自己的实现方案吧
此时再重新看一下这三者的一些区别
1.吞吐量
为什么他们的吞吐量相差那么多呢?
RabbitMQ最慢,尽管它也做了很多优化,但是没用到零拷贝技术,每个连接都是单线程的
而RocketMQ相对快了些,他用多线程,预读取,零拷贝等技术,提升了吞吐量
Kafka更是使用了大量优化策略,文件结构,索引(根据offset找数据),零拷贝,数据压缩等方法,使得它的吞吐量得到了极大的提升
2.订阅方式
这里的区别,主要是由于他们各自的结构决定的
没什么好说的





