redis详解(一)redis基础
一、引言
1.为何要有redis?只用mysql不行吗?
因为mysql为了保证数据安全性,所以每次交互都要落盘,即与磁盘进行交互
众所周知,磁盘访问的速度是很慢的,所以mysql这种方式极大的限制了高并发与高速访问的速度
2.那么redis为什么能做到那么快呢?
因为mysql是与磁盘进行交互所以比较慢,所以redis就将操作都在内存中进行,所以它是一个内存型数据库,由此使得redis速度很快,此外还有一些其他措施保证redis速度,如下
- 它是一个内存型数据库:所以访问不需要与磁盘进行交互,内存会快很多
- 它使用单线程进行操作:减少了上下文切换等消耗
- 它使用了IO多路复用技术:极大的提升了单线程的速度
- Redis 2.x版本使用的是select。
- Redis 3.x版本开始引入了Epoll,并在Redis 4.x版本中成为默认的IO多路复用机制。
- Redis 6.x版本中新增了IOCP支持,并在Windows平台上成为默认的IO多路复用机制。
- 它本身是Key-value结构:类似hashmap,访问速度接近O(1)
- 底层数据结构:跳表,sds等采用了空间换时间的思路
3.CAP理论
CAP 理论是指在分布式系统中,不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)这三个特性,最多只能同时满足其中两个
redis本质上是一个AP模型,即更加重视可用性和分区容错性,对于一致性要求并不是那么高,因此它的速度在一定程度上也是牺牲一致性来换取的
由此也可以得知,对于数据一致性要求高的场景,就尽量不要选用redis,因为它的优点是快,并不追求数据一致性,如果放到强一致性的场景,并不适合使用redis
二、数据结构
字典
1.dict 字典
redis底层数据结构之一,两种基础数据类型hash和zset底层都有采用这种数据结构
首先看下server.h中,最外层结构redisDb的定义
1 | typedef struct redisDb { |
由上面代码,可见其大量用到了dict的数据结构,它是存储在dict.h文件中定义的数据结果,称为字典,下面是字典数据结构
1 | typedef struct dict { |
这里用到了dictht结构的哈希表,它也在dict.h文件中定义,那它的结构是怎样的呢?如下
1 | typedef struct dictht { |
再看一下同样在dict.h文件中定义的dictEntry结构,它是类似hashmap的结构
1 | typedef struct dictEntry { |
redisObject结构如下
1 | typedef struct redisObject { |
看了那么多数据结构,那么他们的关系是怎样的呢?参考下图
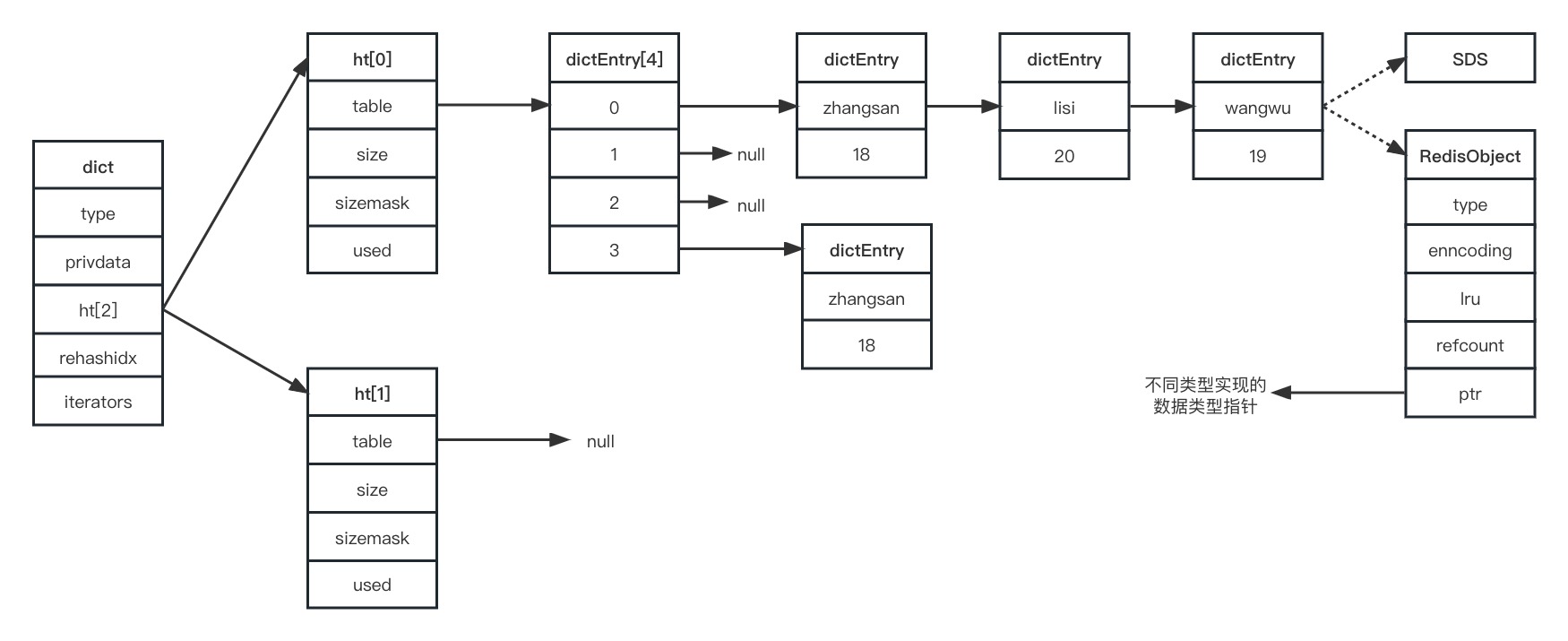
则由上面定义与关系图,可总结字典结构的一些数据结构关系如下:
redisDb包含了所有 Redis 数据库的状态,每个数据库通过dict实现一个键值对的哈希表。dict是 Redis 的哈希表实现,内部使用dictht结构体实现哈希表,dictEntry结构体表示哈希表中一个键值对。redisObject是 Redis 中非常重要的一个结构体,用于表示 Redis 中的所有数据对象,包括字符串、列表、哈希、集合等等。redisObject包含了该对象的类型、编码方式、引用计数等信息,以及指向实际值的指针
h[0]是正常情况下用来存储数据的数据结构,h[1]是扩容时使用的临时空间
dictEntry构成一个table表存储在h[0]当中,每个位置由链表结构组成
整体结构类似java集合中的hashMap结构,即数组+链表
只是要注意,链表的每个节点中存储的value使用redisObject结构,这个结构类型通过type来指明
链表部分,使用头插法插入新数据,因为redis是单线程操作,所以不怕出现死链情况
头插就可以免去遍历到链表结尾的过程了
2.字典扩容
1)扩容时机
注意,在上面的dictht结构中
used参数,用来标识已经使用的桶数量
size参数,表示已经存储的键值对数量
因此扩容时机就是依据这两个参数来判断
- 无子进程在fork刷盘时,used >= size 的时候 进行扩容
- 有子进程在刷盘时,要used >= size * 5
之所以这样设计,是为了使得资源合理利用
2)扩容流程
在早期的redis3.x及以前,扩容数组大小是直接取h[0].size * 2,类似hashMap中的扩容机制
但是在redis4.0及之后,为了更高效的扩容,采用了渐进式迁移的方式,因此扩容大小也修改成了新数组为ht[0].used * 2向上取2的幂,下面是扩容流程
- 判断是否扩容:当满足我扩容条件,触发扩容时,判断是否在扩容,如果在扩容,或者 扩容的大小跟我现在的ht[0].size一样,这次扩容不做。
- new新数组:new一个新的dictht,大小为ht[0].used * 2(但是必须向上2的幂,比如6 ,那么大小为8) ,并且ht[1]=新创建的dictht。
- 渐进式数据迁移:我们有个更大的table了,但是需要把数据迁移到ht[1].table ,所以将 dict的rehashidx(数据迁移的偏移量)赋值为0 ,代表可以进行数据迁移了,也就是可以rehash了。
- 数组指向修改:等待数据迁移完成,数据不会马上迁移,而是采用渐进式rehash,慢慢的把数据迁移到ht[1]
- 当数据迁移完成,ht[0].table=ht[1] ,ht[1] .table = NULL、ht[1] .size = 0、ht[1] .sizemask = 0、 ht[1] .used = 0;
- 把dict的rehashidex=-1
3.渐进式迁移
思考:为什么会出现渐进式数据迁移呢?
假如一次性把数据迁移会很耗时间,会让单条指令等待很久很久,会形成阻塞
所以,Redis采用的是渐进式Rehash,所谓渐进式,就是慢慢的,不会一次性把所有数据迁移
那么,什么时候会触发迁移呢?又是如何迁移的?
- 每次进行key的crud操作都会进行一个hash桶的数据迁移
- 定时任务,进行部分数据迁移
1)crud触发迁移
在源码中,每次增删改都会触发**_dictRehashStep**方法,如下
1 | // 这个代码在增删改查的方法中都会调用 |
_dictRehashStep里面调用了dictRehash
1 | static void _dictRehashStep(dict *d){ |
下面看看dictRehash
1 | static void dictRehash(dict *d, int n) { |
dictRehash是Redis中扩容哈希表的过程,它会将原哈希表ht[0]中的所有元素重新计算哈希值并移动到新哈希表ht[1]中对应的位置。
通过这种方式,可以避免扩容过程中的数据丢失,同时也保证了扩容操作的高效性和可扩展性。
在rehash操作过程中,为了避免耗时过长而造成服务不可用,Redis会将操作分批进行,并交给事件循环处理。
2)定时处理
配置文件中可以修改多久执行一次定时任务
下面是定时任务流程,不再看源码
- 选任务:Redis定时从任务队列中选取一定数量的任务。
- 算权重:对于每个选中的任务,计算出任务的执行权重。
- 排序:根据权重排序,选出最高的一批任务进行执行。
- 迁移:执行任务时将需要迁移的键的数据从源节点迁移到目标节点。
- 同步:迁移过程中会进行增量同步,确保数据的一致性。
- 删除:迁移完成后,源节点上的键会被删除。
- 执行完一批任务后,如果任务队列中还有剩余的任务,则返回第二步,继续选取任务进行执行。
- 如果任务队列中没有剩余任务,则等待一定时间后再次从任务队列中选取任务。
数据量较大时,hash和set的底层结构都采用的dictht
SDS
1.数据结构
1 | typedef char *sds; |
SDS可以看作是一个可以支持动态扩容的数组结构
2.扩容与缩容
SDS使用空间预分配和惰性空间释放的方式,可以避免频繁的内存分配和释放,从而提高了内存的利用率,减少了内存碎片的产生
1)空间预分配
在SDS扩容时,预先分配一定量的额外空间,避免频繁的内存重新分配操作
SDS长度如果小于1MB,预分配跟长度一样的,大于1M,每次跟len的大小多1M
2)惰性空间释放
当SDS的长度缩短时,并不立即释放多余的空间,而是等待下一次扩容时再进行释放
五种基本数据类型之中,String在数据量不大时底层采用SDS实现,数据量大了采用字节数组实现
压缩列表 ziplist
压缩列表(ziplist)是 Redis 内部使用的一种紧凑的、列表式数据结构。它可以存储多个键值对,每个键值对占用一段连续的内存空间,且支持在列表的两端进行高效的插入和删除操作
压缩列表会根据存入的数据的不同类型以及不同大小,分配不同大小的空间。所以是为了节省内存而采用的。因为是一块完整的内存空间,当里面的元素发生变更时,会产生连锁更
新,严重影响我们的访问性能。所以,只适用于数据量比较小的场景
在redis之中,list,set和zset在数据量不大并满足一定条件时,都会采用压缩链表作为存储结构
例如hash类型,当hash对象同时满足以下两个条件的时候,使用ziplist编码:
- 哈希对象保存的键值对数量<512个
- 所有的键值对的健和值的字符串长度都<64byte(一个英文字母一个字节)
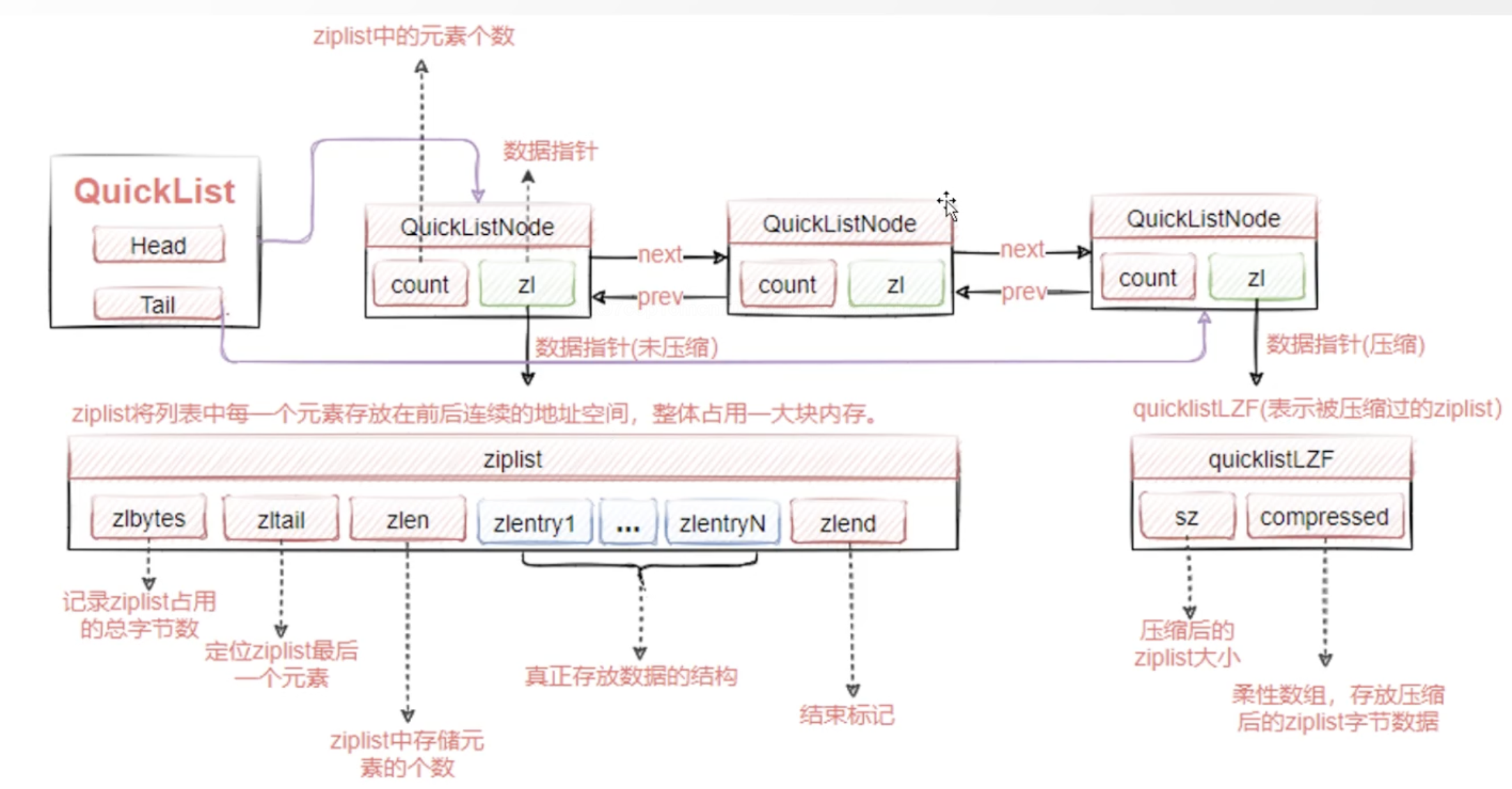
快速列表 quicklist
快速列表(quicklist)是 Redis 中用于实现列表类型的一种数据结构,它是一种紧凑的、节约内存的、压缩列表的变种。
快速列表可以保存多个元素,并且每个元素可以是不同的类型。快速列表的结构非常紧凑,可以大大减少存储空间的占用。
把连锁更新的连续块儿,拆成了node节点,连成链表,即双向链表节点里面会持有一个ziplist;本质上还是用了ziplist;多少个ziplist拼成一个node可在配置文件中配置
所以一定程度上可解决连锁更新的问题
整体结构图如下
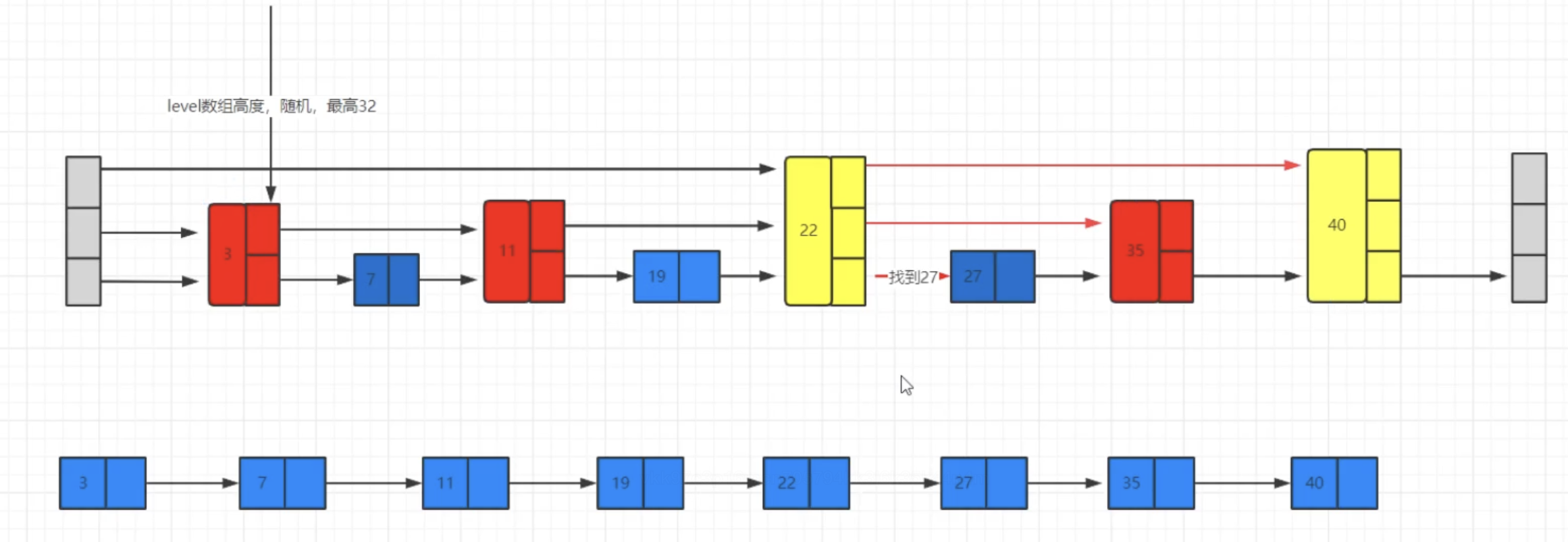
跳表
跳表(Skip List)是一种随机化数据结构,可以用来实现有序的数据集合,也可以用来加速查找操作。Redis中的有序集合(Sorted Set)就是通过跳表实现的
数据结构定义如下:
1 | /* |
本质上就是通过设置不同层level来构建不同层级的索引,通过索引加速查询
图解
三、基础数据类型
1.String
实现:
在数据量较小时,使用SDS实现
数据量较大则采用字节数组实现
适用场景:
- 缓存
- 全局id
- 计数器
- 限流
- 用一个值记录访问次数,达到就实现限流方案,也算是计数器变种
2.Hash
实现:
数据量较小时,使用ziplist实现
数据量较大时,使用dictht实现
适用场景:
适合存储对象等结构化数据
3.List
实现:
数据量较小时,使用ziplist实现
数据量较大时,使用quicklist实现
适用场景:
- 分布式队列
- 消息队列
- 异步消息通知
4.Set
实现:
数据量较小时,使用ziplist实现
数据量较大时,使用dictht实现,只用key不用value,类似Java的Set
适用场景:
适用于存储不重复的数据,如用户ID、IP地址、标签等
5.ZSet
它的排序是通过每个数据携带一个score来实现的
实现:
数据量较小时,使用ziplist实现
数据量较大时,使用skiplist实现
适用场景:
适用于按照分数排序的数据,如排行榜、优先级队列等
四、内存管理
要区分什么是过期策略,什么是淘汰策略
1.过期策略
为了保证内存的利用率,会把过期数据进行删除,删除设置了过期时间,并且到期的数据
1)惰性过期
要用的时候,会判断是否过期
缺点是脏数据一直占据内存,很不友好
2)定期清理
- 去设置了过期时间的key里面拿
- 以hash桶为维度,扫到20个为止最多拿400个空桶
- 找到里面过期的key,进行删除
- 过期的比例超过10,就再次扫描
- 最多扫描16次,超次截止
所以,过期策略就是怎样淘汰那些设置了过期时间的过期数据
这里有一个面试题,就是当redis大量key同时过期,会导致什么情况?
想问的是当大量key同时过期,主线程会一直在扫描这些key进行过期处理,导致主线程阻塞
解决方案:
- 设置过期时间时,将过期时间分散开来
- 通过参数配置,减少主线程的扫描时间
2.淘汰策略
假设没有设置过期时间,或者设置的过期时间没到期,但是内存满了,内存里面的数据都是有效数据,这时需要有一个淘汰策略
在redis里面,淘汰策略每次不会删除太多数据,因为这时候的数据并没有过期,所以只会按照一定策略将数据删除的正好能够放进新数据即可
1)淘汰算法
- 默认情况下,不能写,能读,写入报错
- 所有数据里使用lru/lfu
- 过期数据里使用lru/lfu
- ttl淘汰快过期数据
- random随机
2)淘汰池
如何保证不删太多,删的正好够放入新key呢?
就是用淘汰池,从里面删除正好数量的数据,实行末位淘汰机制,从最后面开始删
redis的淘汰并不是全量范围内淘汰,而是根据批次选择,放入淘汰池最应该被淘汰的key
注意,这里并不删除key,只是放里面最应该淘汰的






